
By Josh Symonds, March 7, 2017, AppDynamics.
Final Thoughts
By relying on auto scaling groups, AMIs, and a sensible provisioning system, you can create a system that is completely repeatable and consistent. Any server could go down and be replaced, or 10 more servers could enter your load balancer, and the process would be seamless, automatic, and almost invisible to you.

And that’s the secret why Amazon’s services rarely go down. Not the hundreds of engineers, or dozens of datacenters, or even the clever products: It’s the automation. Failure happens, but if you detect it early, isolate it as much as possible, and recover from it seamlessly—all without requiring human intervention—you’ll be back on your feet before you even knew a problem occurred.
There are plenty of potential concerns with powerful automated systems like this. How do you ensure new servers are ones provisioned by you, and not an attacker trying to join nodes to your cluster? How do you make sure transmitted copies of your databases aren’t compromised? How do you prevent a thousand nodes from accidentally starting up and dropping a massive AWS bill into your lap? This overview of the techniques AWS leverages to prevent downtime and isolate failure should serve as a good jumping-off point to those more complicated concepts. Ultimately, downtime is impossible to prevent, but you can keep it from broadly affecting your customers. Working to keep failure contained and recovery as rapid as possible leads to a better experience both for you and your users.
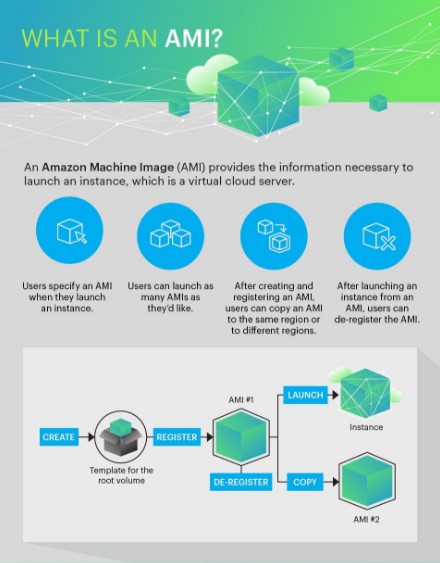
You can view the full infographic here.
Read part 1 of this 3 part series by clicking here.
Read part 2 of this 3 part series by clicking here.