
By Josh Symonds, March 7, 2017, AppDynamics.
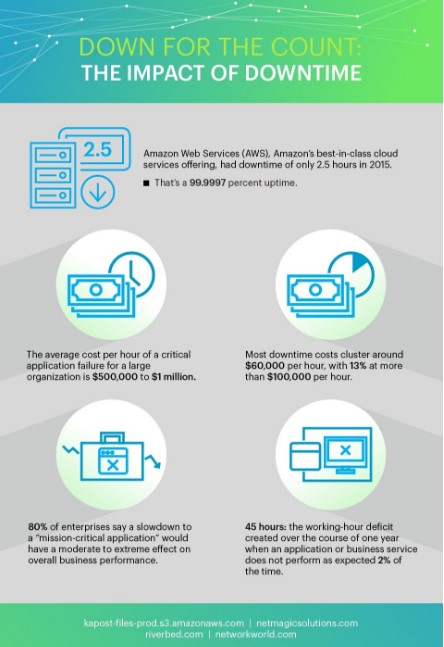
Amazon Web Services (AWS), Amazon’s best-in-class cloud services offering, had downtime of only 2.5 hours in 2015. You may think their uptime of 99.9997 percent had something to do with an engineering team of hundreds, a budget of billions, or dozens of data centers across the globe—but you’d be wrong. Amazon’s website, video, and music offerings, and even AWS itself, all leverage multiple AWS products to get five nines of availability, and those are the same products we get to use as consumers. With some clever engineering and good service decisions, anyone can get uptime numbers close to Amazon’s for only a fraction of the cost.
But before we discuss specific techniques to keep your site constantly available, we need to accept a difficult reality: Downtime is inevitable. Even Google was offline in 2015, and if the single largest website can’t get 100 percent uptime, you can be sure it’s impossible for your company to do so too. Instead of trying to prevent downtime, reframe your thinking and do everything you can to make sure your service is as usable as possible even while failure occurs, and then recover from it as quickly as possible.
Here’s how to architect an application to isolate failure, recover rapidly from downtime, and scale in the face of heavy load. (Though this is only a brief overview: there are plenty of great resources online for more detailed descriptions. For example, don’t be afraid to dive into your cloud provider’s documentation. It’s the single best source for discovering all the amazing things they can do for you.)
Architecture and Failure Mitigation
Let’s begin by considering your current web application. If your primary database were to go down, how many services would be affected? Would your site be usable at all? How quickly would customers notice?
If your answers are “everything,” “not at all,” and “immediately” you may want to consider a more distributed, failure-resistant application architecture. Microservices—that is, many different, small applications that work together to act like a larger app—are extremely popular as an engineering paradigm. The failure of an individual service is less noticeable to all clients.
For example, consider a basic shop application. If it were all one big service, failure of the database takes the entire site offline; no one can use it at all, even just to browse products or plan purchases. But now let’s say you have microservices instead of a monolith. Instead of a single shop application, perhaps you have an authentication service to login users, a product service to browse the shop, and an order fulfillment service to charge customers and ship goods. A failure in the order fulfillment database means that only people who try to ship see errors.
Losing an element of your operation isn’t ideal, but it’s not anywhere near as bad as having your entire site unavailable. Only a small fraction of customers will be affected, while everyone else can happily browse your store as if nothing was going wrong. And with proper logging, you can note the prospects that had failed requests and reach out to them personally afterward, apologizing for the downtime and hopefully still converting them into paying customers.
This is all possible with a monolithic app, but microservices distribute failure and better isolate it to specific parts of a system. You won’t prevent downtime; instead, you’ll make it affect less people, which is a much more achievable goal.
Databases, Automatic Failover, and Preventing Data Loss
It’s 2 a.m. and a database stops working. What happens to your website? What happens to the data in your database? How long will you be offline?
This used to be the sysadmin nightmare scenario: pray the last backup was usable and recent, downtime would only be a few hours, only a day’s worth of data perished. But nowadays the story is very different, thanks in part to Amazon but also to the power and flexibility of most database software.
If you use the AWS Relational Database Service (RDS), you get daily backups for free, and restoration of a backup is just a click away. Better yet, with a multi-availability zone database, you’re likely to have no downtime at all and the entire database failure will be invisible.
With a multi-AZ database, Amazon keeps an up-to-date copy of your database in another availability zone: a logically separate datacenter from wherever your primary database is. An internet outage, a power blip, or even a comet can take out the primary availability zone, and Amazon will detect the downtime and automatically promote the database copy to be your main database. The process is seamless and happens immediately—chances are, you won’t even experience any data loss.
But availability zones are geographically close together. All of Amazon’s us-east-1 datacenters are in Virginia, only a few miles from each other. Let’s say you also want to protect against the complete failure of all systems in the United States and keep a current copy of your data in Europe or Asia. Here, RDS offers cross-region read replicas that leverage the underlying database technology to create consistent database copies that can be promoted to full-fledged primaries at the touch of a button.
Both MySQL and PostgreSQL, the two most popular relational database systems on the market and available as RDS database drivers, offer native capabilities to ship database events to external follower databases as they occur. Here, RDS takes advantage of a feature that anyone can use, though with Amazon’s strong consumer focus, it’s significantly easier to set up in RDS than to do it manually. Typically, data is shipped to followers simultaneously to data being committed to the primary. Unfortunately, across a continent, you’re looking at a data loss window of about 200 to 500 milliseconds, because an event must be sent from your primary database and be read by the follower.
Still, for recovering a cross-continental consistent backup system, 500 milliseconds is much better than hours. So next time your database fails in the middle of the night, your monitoring service won’t even wake you. Instead you can read about it in the morning—if you can even detect that it occurred. And that means no downtime and no unhappy customers.
You can view the full infographic here. In out next two installments Josh covers the additional segments of the infographic not covered in this first installment.
Read part 2 of this 3 part series by clicking here.